
Article Contributed by Chris Holmes, OGC Visiting Fellow –
In my previous post I laid out the vision for Cloud-Native Geospatial, but with this post, I want to get into the details of what is needed. I’ll lay out the key areas where foundational standards are needed, and then survey the current status of each area. They range from quite well-established to quite speculative, but all are eminently achievable. And then I’ll dive deep into the area I ended up focusing on the most in these last few months as an OGC Visiting Fellow.
Components Needed
There are a few key components needed to represent diverse location information on the cloud. These sit ‘below’ an API – they are simply resources and formats. Together these components provide a solid foundation to represent most any geospatial information on the cloud. They should be compatible with APIs; they may serve to be responses to requests, as JSON resources or streaming formats. But it should also be completely possible to simply store these on a cloud storage object store (S3, GCP, etc). Those in turn will often be read by more capable APIs to do cool operations, but they don’t need to.
The core that I see is:
- Core Raster format: A solid cloud-native format to handle satellite imagery, DEMs, data products derived primarily from satellite imagery, etc.
- Multi-dimensional Raster format: A cloud format able to handle massive data cubes, like the results of weather forecasts, temperature over time and elevation, climate modeling, etc. This is the traditional space of NetCDF / HDF.
- Core vector formats: A vector data equivalent to Cloud Optimized GeoTIFF would be ideal, but the diverse requirements of fast display and on-the-fly deep analysis may not be easily combinable, so we may end up with more than one format here.
- Point cloud format: A cloud format that works like COG, but enables streaming display and on-the-fly analysis of point clouds.
- Collection & Dataset Metadata: The title, description, license, spatial and temporal bounds, keywords, etc. that enable search. For the cloud-native geospatial baseline, this should focus on being ‘crawlable’, and link to actual formats. It should support diverse data types – vector data, raster data, point clouds, multi-dimensional data cubes, geo-located video, 3d portrayals, etc. – and should be flexible enough to work with any data. It should be fundamentally geospatial-focused, and not try to generically describe any data.
- Granule / Scene level / ‘asset’ Metadata: A flexible metadata object with common fields for describing particular data capture domains and linking to the actual data files.
Most of these have at least the start of an answer in our worldwide geospatial community, if not a robust solution:
- Core Raster format : Today this is Cloud Optimized GeoTIFF (COG). It is in the process of becoming an official OGC standard and has already seen incredible adoption in a wide variety of places. It’s really the foundational cloud-native geo format that has proven what is possible. It is worth noting that it may not be the end-all for cloud raster formats, as one could see a more optimized image format that is smaller and faster. But it would likely be some more general image format that our community adds ‘geo’ to like we did with TIFF. COGs will rule for a while, since the backward compatibility with legacy tools is hard to beat while we’re still early in the transition to cloud-first geospatial infrastructure.
- Multi-dimensional Raster format : There’s also already a great answer here with zarr. It is in the process of being adopted as an OGC Community Standard, with the adoption vote starting soon. It’s also being embraced by NetCDF, and has seen significant uptake in the climate community.
- Core vector formats: There is as of yet no great answer here. I’ll discuss the landscape and various possibilities in a future blog post.
- Point cloud format : Howard Butler’s new COPC format is a ‘Range-readable, compressed, organized LASzip specification’ that hits all the same notes as Cloud-Optimized GeoTIFF and likely will see rapid adoption.
- Collection & Dataset Metadata: has a solid core with the OGC API – Features ‘Collection’ construct. The STAC Collection then extends that, and the OGC API – Record provides a GeoJSON equivalent that can be used as a return in search queries. But these parts haven’t quite all connected in a coherent way, and the full ‘static’ (just upload to S3) usage hadn’t been fully fleshed out. This was the main focus of my work the last few months, so I’ll dive in deeper below.
- Granule / Scene level / ‘asset’ Metadata: is where the SpatioTemporal Asset Catalog (STAC) specification that’s been my main focus the last few years has played, and it’s seeing really great adoption after recently reaching version 1.0.0.
What about Tiles?
For me, the jury is still out if a web tiles specification really belongs in a true cloud-native geospatial baseline. I believe for raster tiles (png, jpeg, etc) they don’t make sense, as a Cloud-Optimized GeoTIFF can easily be transformed on the fly into web tiles, using serverless tilers like Titiler. So the pattern is to use a good cloud-native format that enables on-the-fly rendering and processing in the form clients need. Tiles are essential for browser-based clients, but other tools are better served accessing the data directly. Once the OGC API – Tiles standard is finalized it will likely make good sense to create a ‘Tile metadata building block’ that can serve as a cloud-native format to point clients at tiles.
For vector tiles I would consider both MVTs and PBFs as cloud-native geospatial formats, in that they can sit at rest on a cloud storage bucket and be used by various applications. But I do think there is potential for a good cloud-native vector format to work like COGs, with a serverless tile server that can render vector tiles on the fly. I’ll explore this idea more deeply in a future post on vector formats.
How do OGC APIs fit in?
The OGC API initiative is a reinvention of the OGC W*S baseline into more modern JSON/REST API’s. Generally, it sits one level ‘above’ the cloud-native geospatial constructs discussed here, defining API interfaces for services that would use the cloud-native formats (but could also use more traditional formats and spatial databases). They enable a lot more, like dynamic search or on-the-fly processing of data, but also require more. Most of the cloud-native metadata constructs have been extracted from the APIs, so the cloud-native variants should be compatible with the OGC APIs, just a lot less capable (though also far easier to implement).
An ideal ecosystem would see most data stored in cloud-native geospatial formats, and then a wide array of services on top of those, with most of them implementing OGC API interfaces. In the future, it will hopefully be trivial to install a server or even a serverless function that provides the richer OGC API querying on top of the cloud-native metadata and formats.
Towards Cloud-Native Geospatial Collection Metadata
As mentioned above, a majority of my OGC Visiting Fellow time the last few months has gone into sorting out a ‘cloud-native geospatial collection’. There are a few different aspects to this.
A static OGC Collection
One of the most powerful constructs that has emerged in STAC’s evolution is the ‘static STAC’. See the Static Spatiotemporal Asset Catalogs in Depth post for a great summary of what they are and how they work. To quote the ‘best practices’ of the 1.0.0 version of the spec:
A static catalog is an implementation of the STAC specification that does not respond dynamically to requests. It is simply a set of files on a web server that link to one another in a way that can be crawled, often stored in an cloud storage service like Amazon S3, Azure Storage and Google Cloud Storage…A static catalog can only really be crawled by search engines and active catalogs; it can not respond to queries. But it is incredibly reliable, as there are no moving parts, no clusters or databases to maintain.
It has proven to be a very popular way to publish STAC data, making good on the vision in my previous blog post of being able to upload data to the cloud and have it ‘just work’.
But while STAC pioneered clear static options for both individual items of imagery and other spatiotemporal assets, as well as collections of that type of data, there had been missing an equivalent ‘static collection’ for vector data. The OGC API – Feature Collection (that STAC extends for its Collection) as specified is only part of an API response, not an independent JSON resource that can be used independently. But it was a well-designed modular part, and Clemens Portele and Peter Vretanos, the editors of the Features specification, were always supportive of pulling it out.
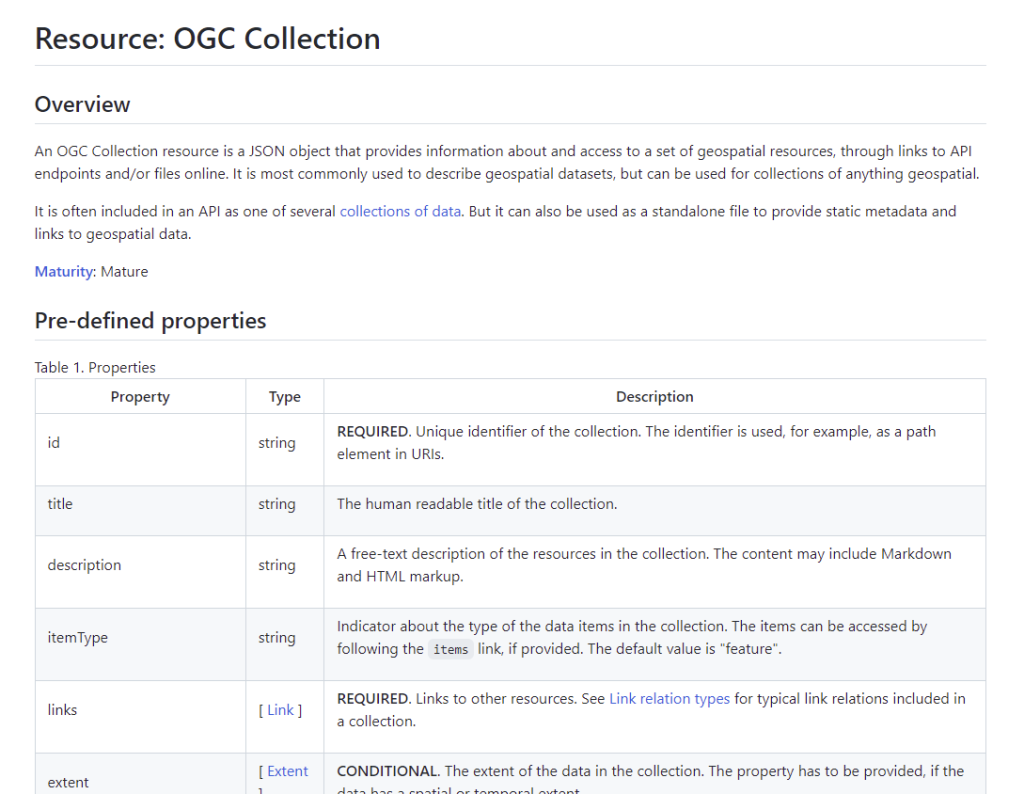
I made a rough attempt in an experimental github repository. But then Clemens ran with another idea we had been kicking around of making true small granular building blocks from the OGC API baseline (I’ll try to make a full post on that in the future). This resulted in a very clean ‘Collection’, extracted from OGC API – Features, but written as an independent JSON resource that could be re-used in any context. And thus we have a real ‘static OGC Collection’, capable of living statically on cloud storage. This can point at a GeoJSON, GeoPackage, Shapefile or any new more cloud-native format. You can see an example of this in a repository I made to experiment with examples of static collections. That one has multiple representations of the same data as different formats, but it could easily just have one.
Records + STAC alignment
Another large chunk of my time went into work that isn’t a direct cloud-native task: fully aligning STAC with OGC API – Records. Many have been unsure of the exact relationship between the two specs, though I always had clear (but not well communicated) thoughts. So the last few months have enabled the time to fully sync with the core Records team and get agreement on the path forward. The quick version is that Records API has a real role to play in STAC, as we’ve been holding off on ‘collection-level search’, since we wanted to fully align that with Records. But the confusing part is that a Records API can also be used to search STAC-like items, and indeed is designed for search of almost anything.
So the ‘aha’ moment was realizing that the Records spec authors have always had in mind a ‘Data Record’, which is really what STAC needs, which is a bit more specific than a totally general, flexible Record. STAC’s Collection construct is really only focused on what OGC considers ‘datasets’, it’s just that there hasn’t been a clear specification of that construct in the emerging OGC API baseline. I’ve started a pull request in the Records repo to add it and then will also propose a ‘Data Collection’ which extends the core OGC Collection with additional fields. A STAC Collection in turn should hopefully align with that Dataset Collection construct. And in the future we’ll work together to have a ‘STAC Record’ that fully aligns a STAC Item with the more general record requirements.
The other cool effect of this sync has been a really nice refactoring of the core Records API specification by Peter Vretanos. The vision has always been that Records API is a Features API, but with some additional functionality (ie sort and richer querying) and a more controlled data model. The new version makes that much more clear, emphasizing the parts that are different from the core OGC APIs, and it should be much easier to align with STAC.
Static Records
This work all nicely laid the foundation for the next cloud-native geospatial component, a crawlable catalog which consists of web-accessible static records! Peter put up an example crawlable catalog (and I have a PR that expands the example with a ‘static OGC collection’ with vector data), which needs a bit more work to align with STAC, but fits with all our cloud-native geospatial principles. So we’ve now got pretty much all the pieces needed for all the right metadata we need for a cloud-native geospatial baseline. Records and Collections are basically two alternate instantiations of the same core data models, one is GeoJSON, making it easy to visualize lots of them together, and the other matches the core OGC API Collection construct that is used extensively. In the short term, the best practice will likely be to make use of both of them, but in time there will likely be tools that easily translate from one to the other, especially if we get the core data models to be completely compatible.
Bringing it all together
So we are tantalizingly close to the full suite of static metadata needed to handle most any cloud-native geospatial data. The main task ahead is to fully align the work in OGC API – Records and – Features to be compatible with STAC, and to better describe all the necessary metadata fields. There are a few ways things are a bit different right now, so it’d be nice to simplify things between the two approaches a bit.
To help show how everything could work together I’ve put up a ‘static ogc examples’ repository to demonstrate how you could have a number of diverse datasets and formats all available from a completely static structure. I’ll keep expanding it and evolving the examples, and flesh out the readmes to show what is happening. And in the future I’ll try to do a blog post going deep into the details.
Future posts will go deeper into more of the state of actual cloud-native geospatial formats. Vector data is where I’ve spent most of my time lately, as there is not a super clear answer. I hope to also spend more time highlighting zarr and copc, as those are two really great efforts that fit in well and really round out a complete ecosystem of formats.